The longer I work in commerce, the more every business starts to look like a data problem wearing a storefront.
I learned it watching a storefront take the blame for someone else's mistake. For weeks it showed the wrong prices. The bug was not in the storefront. Two documents inside the company both claimed to be the price list, and nobody could say which was true. The storefront was publishing a disagreement the business never had.
Small story. The part that stuck with me is not about prices. What a customer touches is the shallowest layer of a company. The real company is the data underneath: what a product is, what it costs, what it is made of, how it moves from the people who make it to the people who buy it. That layer tends to set the ceiling on everything above it.
Product data is the company
As far as I can tell, this holds across industries and sizes. Furniture house, parts distributor, fashion label, marketplace. Strip away the brand and the storefront and what is left is a set of claims about products, and the machinery that keeps those claims true. That machinery is the company. Everything else renders it.
I missed it for a long time myself. It is easy to treat product data as a chore in spreadsheets and a few people's heads, and the storefront as the product. Then you spend on the storefront, and it keeps inheriting whatever the data underneath actually is. You can't really out-design a broken source.
One engine, many renderings
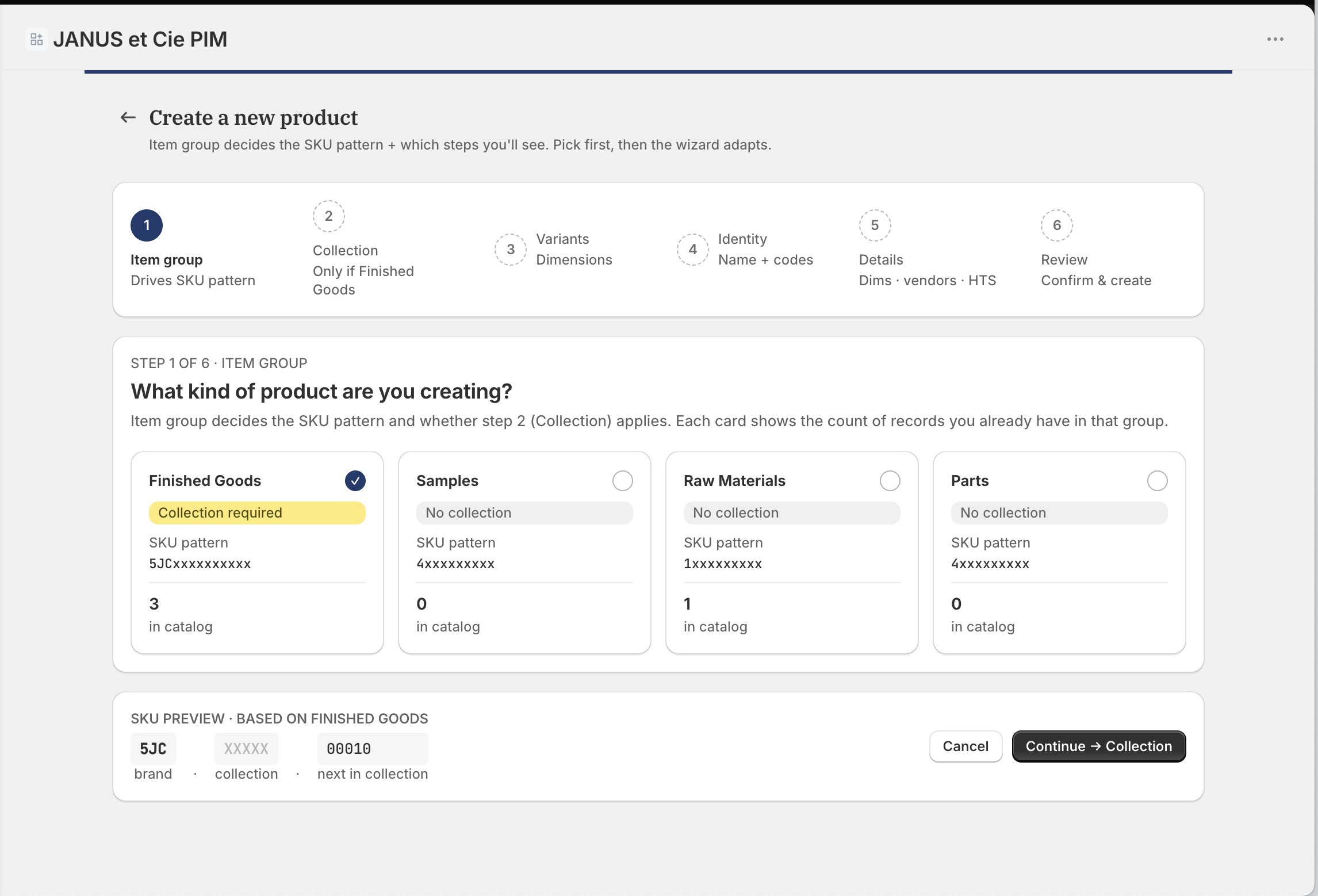
Walk a commerce operation back to its source and there is usually one engine doing the real work. The catalog I rebuilt had three parts, easier to name apart than to pull apart.
A place where the people who make the products describe them. A model, the PIM, where those descriptions become the company's beliefs about each product: variants, rules, price, imagery. A configurator, the rules engine that reads the model, decides what is actually buildable, and hands a settled answer downstream.
Portal feeds model. Model feeds configurator. The flow runs one way. What comes out is read by everything downstream: the storefront, the quoting tool a salesperson uses, the ERP that plans and fulfills the order. Three audiences, three interfaces, one source. None of them author. They read.
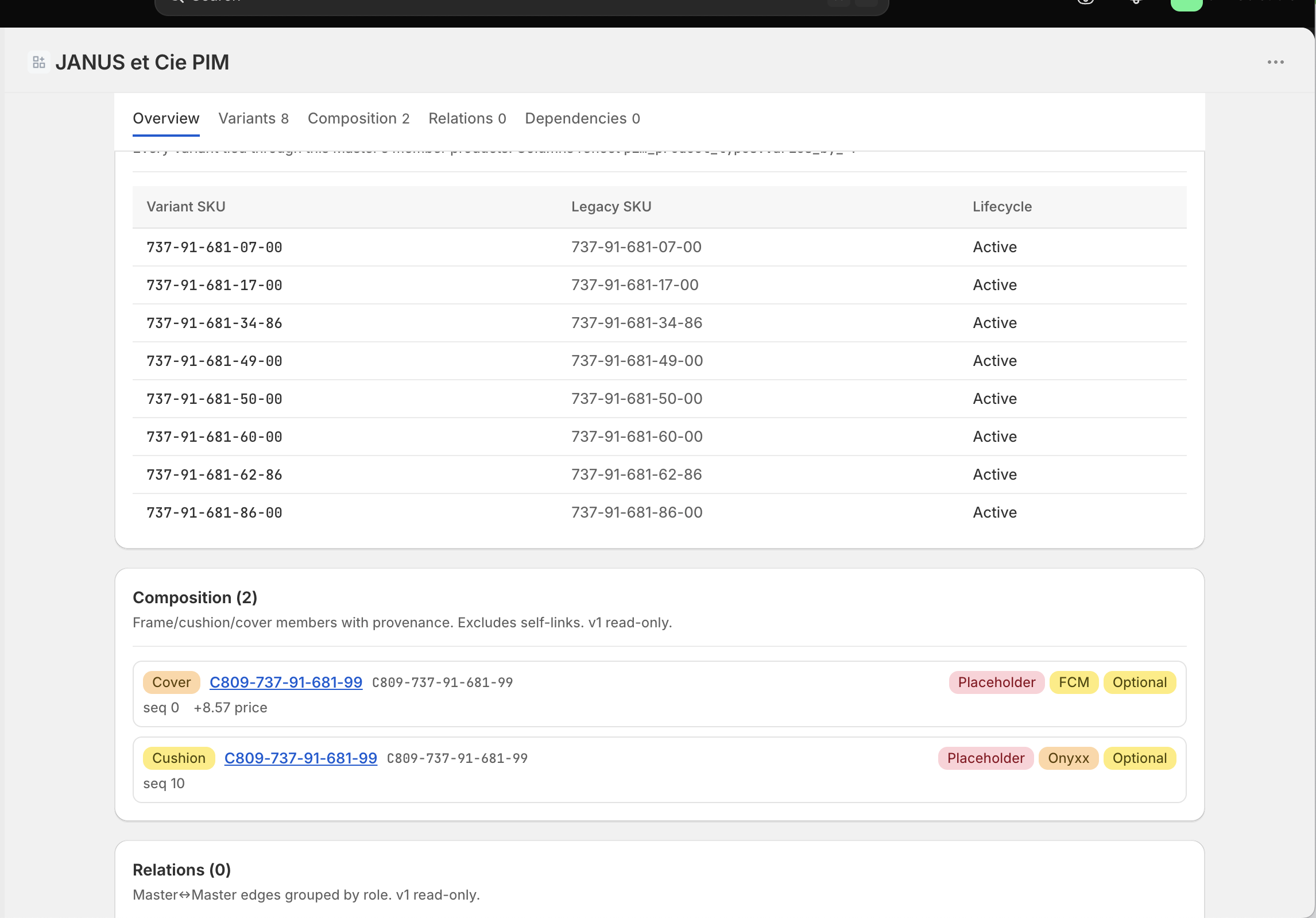
Get the engine right and each new surface is a few weeks of rendering work. Get it wrong and every surface inherits the same defect at once.
A catalog is a set of beliefs
The model in the middle of that engine is not data. It is a set of decisions about what the business believes a product is.
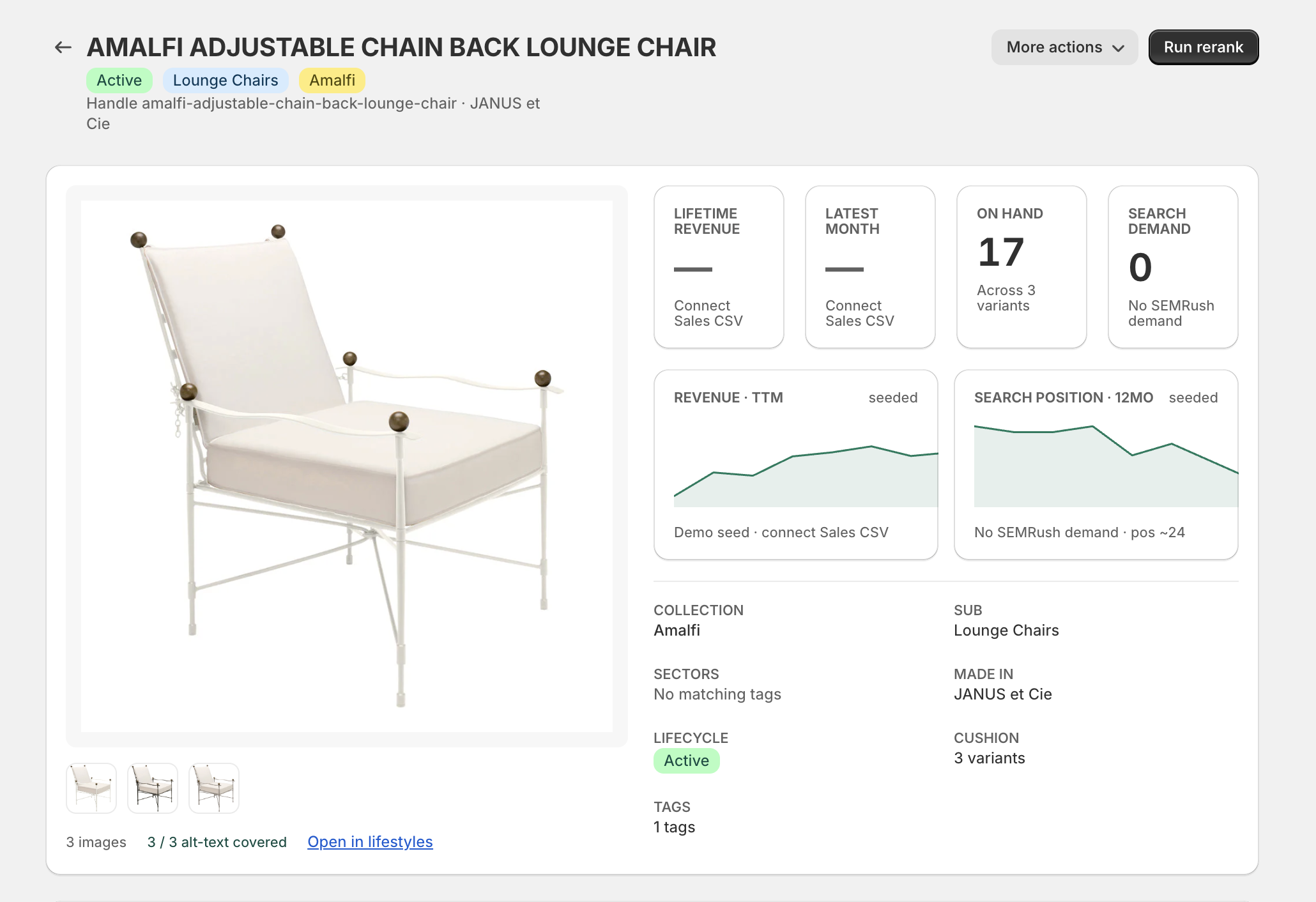
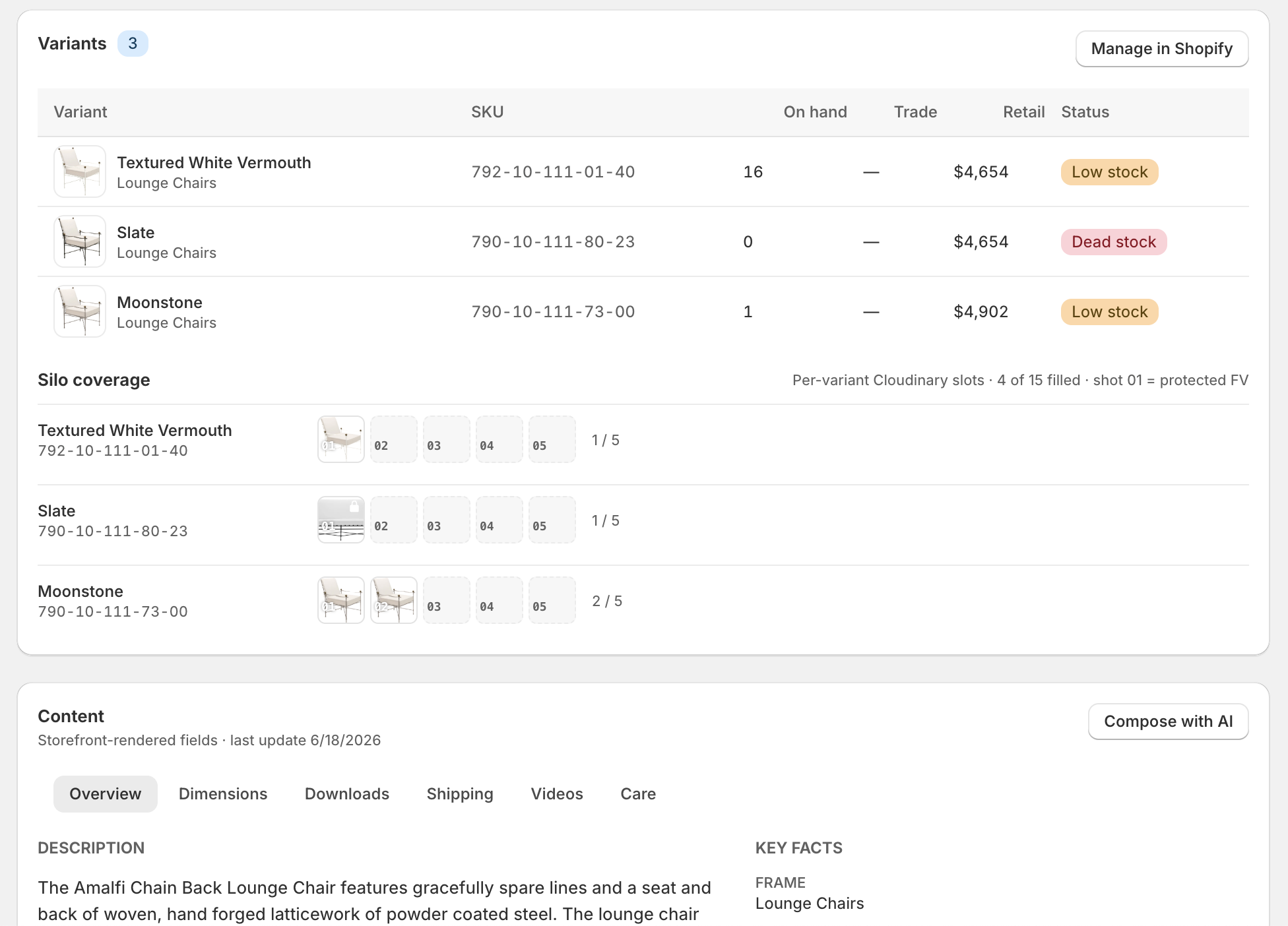
The legacy catalog carried 19,600 SKUs as flat records. Everyone called it twenty thousand products. It was never twenty thousand products. It was about two thousand ideas, each with a few thousand expressions: a finish, a fabric, a dimension. Modeled honestly: 2,200 masters, 7,600 variants. Then everything inherits. Price attaches once. Imagery attaches once. Rules cascade instead of being copied by hand across twenty thousand rows.
The flow is the product
A model that just sits there is a library. The value is the flow: a clean description leaving its source and arriving, unchanged in meaning, everywhere it is needed.
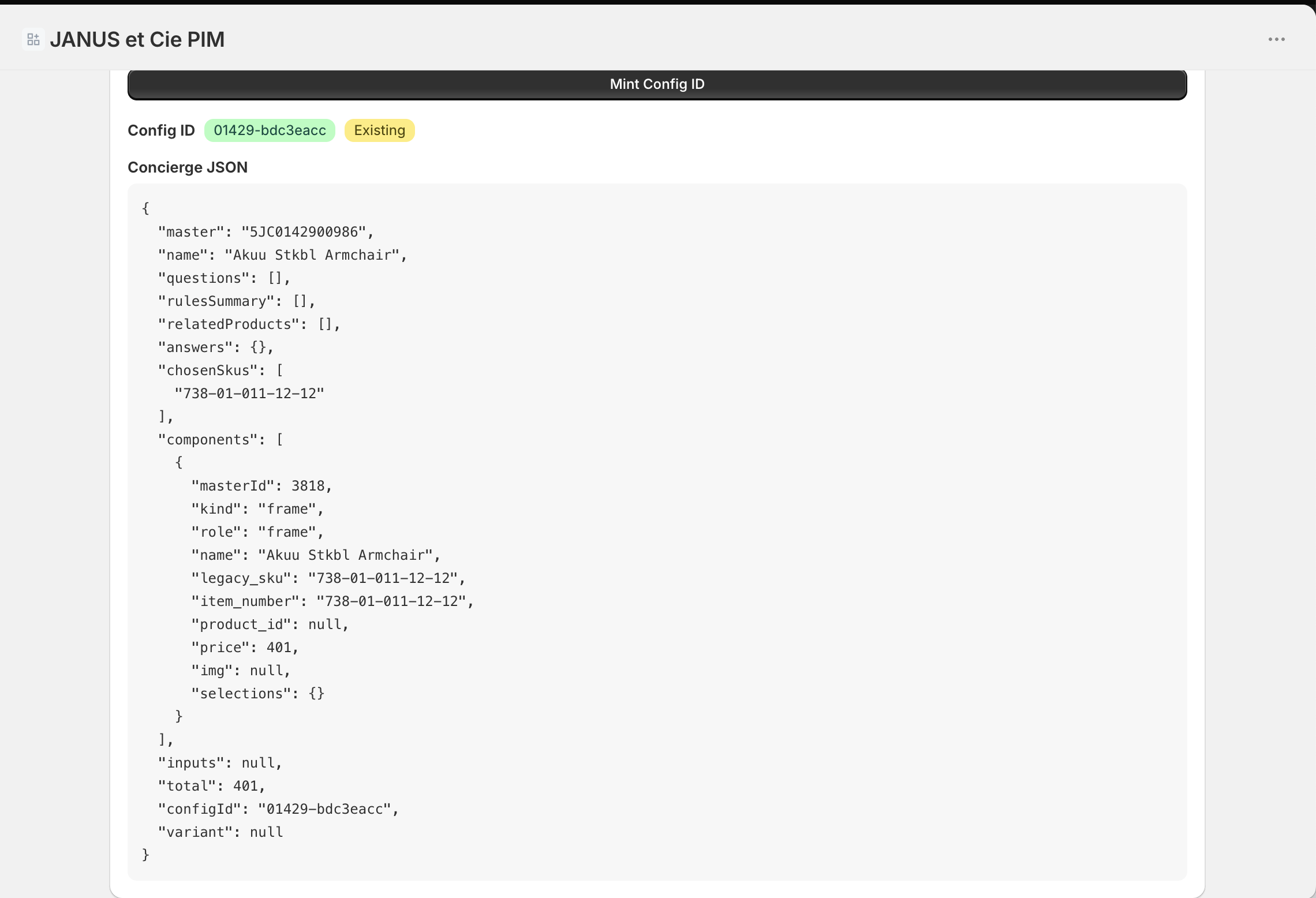
That is the configurator's job. It resolves a buildable spec, prices it, and mints it into one identifier with a structured payload behind it.
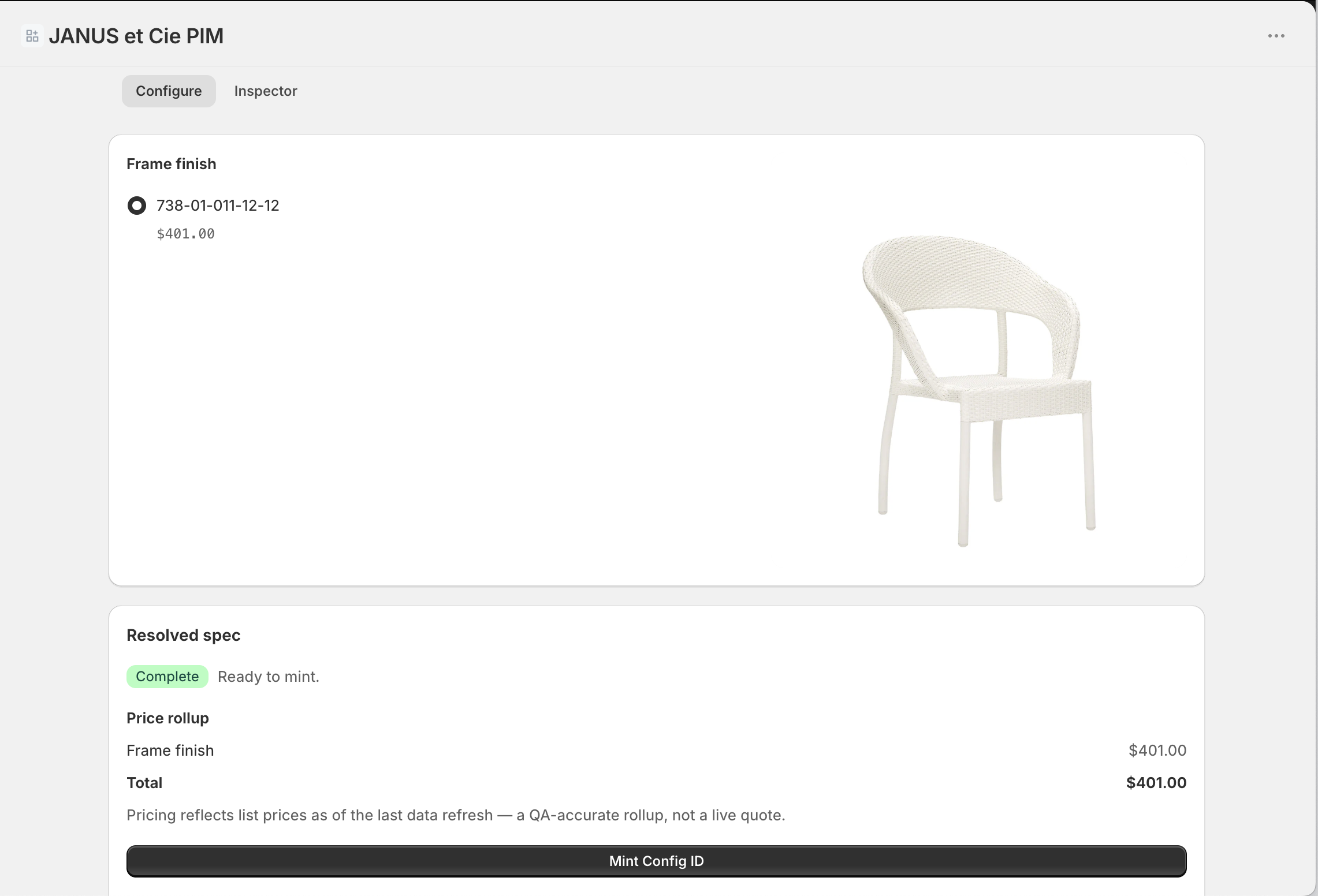
One identifier carries the whole configuration downstream. The quoting tool reads it. The ERP reads it. Nothing is re-keyed, nothing drifts. The three-week disagreement this essay opened with cannot happen here. One source, one flow, one answer.
It is the company, not a layer
The whole thing turns on one move, and the move is almost embarrassingly simple.
The common approach treats digital as a layer. A storefront here, an app there, a configurator bolted onto the front. Each project upgrades a surface, the data underneath stays whatever it was, and every new surface is taught to cope with it.
The systemic approach is barely more work, and for me it changed how I build. The engine is not a tool the company uses. It is the company, written down. So you do not improve the company by improving a rendering. You fix the source, and every rendering improves at once.
That is the quiet power of it. One model, governed once, makes every surface downstream cheaper, faster, and truer. The simplicity is the point. It is not a clever architecture. It is putting the truth in one place and letting everything else read from it.
The stakes just changed
There is a 2026 reason this matters more than it did two years ago. AI is only as smart as the engine under it. An agent cannot reason over a description it cannot read. A decision layer can rank a catalog and explain itself only because the engine made the catalog legible first.
And it is no longer only your agents reading. Language models shop catalogs on a customer's behalf now. They do not see your storefront. They read your record. Which makes me think a company is becoming only as good as its data is legible, and as fast as that data flows.
The storefront depreciates. The substrate compounds.
A storefront is a depreciating asset. Companies replatform it every three to five years, drag the same broken catalog across, and the new one inherits the old problems. The engine is the layer that compounds. Every cleaned relationship, every governed field, every resolved duplicate pays out again on every surface that comes after.
So the first question is not how the storefront should look. It is harder, and I think better. What is a product here, which system holds the truth, and how does that truth flow to everything else? Answer that, and the storefront tends to take care of itself.
Five signs your product data is the bottleneck
- Every feature request starts with a data backfill.
- Nobody can answer "which system holds the truth?" in one sentence.
- The same product is described three different ways in three different tools.
- A product launch requires a meeting.
- Your duplicate count is a feeling, not a number.
Take this as one build, and one person's read of it. The pattern has held everywhere I have looked, and where it is done well it seems to pay for itself fast. If that sounds like your situation, the proof is a storefront you can visit and an engine you cannot see behind it. I wrote up the build as a case study: the architecture, the five decisions, the real numbers. Read the Janus et Cie case study.